|
Jaehun Jung I'm a Ph.D student in computer science at the University of Washington, advised by Yejin Choi. I am also a part-time student researcher in Nvidia Research. My research focuses on how to train and evaluate a model with a model, with minimal human supervision. I am specifically excited in Previously I was an undergrad at Seoul National University, advised by Professor U Kang and Jinwook Seo. I was also a part-time researcher in Kakao Enterprise, where I worked on knowledge-grounded dialogue agents. |

|
Research |
|
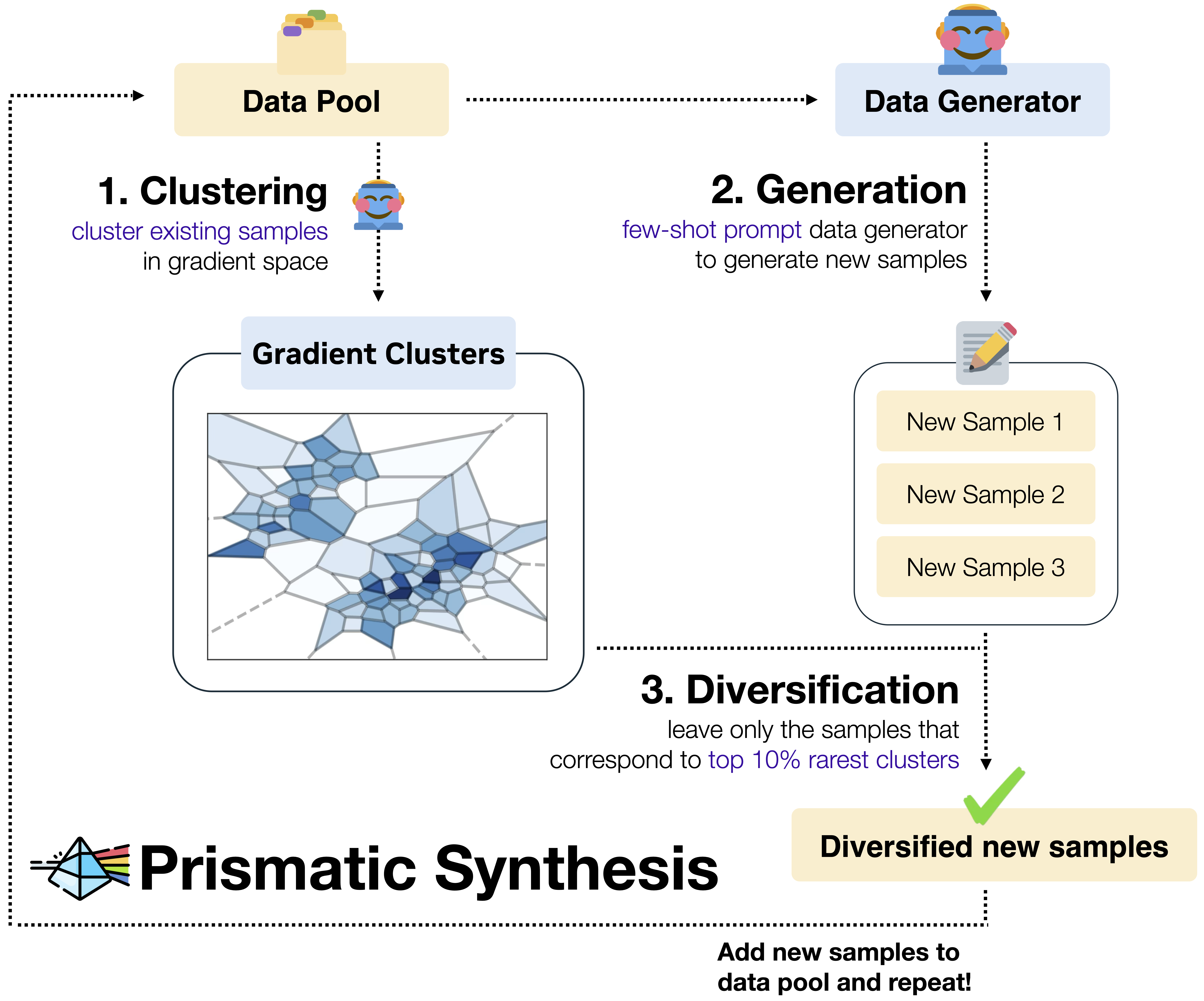
Jaehun Jung, Seungju Han*, Ximing Lu*, Skyler Hallinan*, David Acuna, Shrimai Prabhumoye, Mostafa Patwary, Mohammad Shoeybi, Bryan Catanzaro, Yejin Choi preprint, 2025 project page / paper We show that data diversity (measured by our proposed metric G-Vendi) strongly predicts how the model generalizes after training. We leverage this finding to strategically diversify synthetic reasoning data. Our resulting datasets, despite generated by 32B LLM, leads to better performance in OOD than R1-671B generated & human-verified datasets. |
|
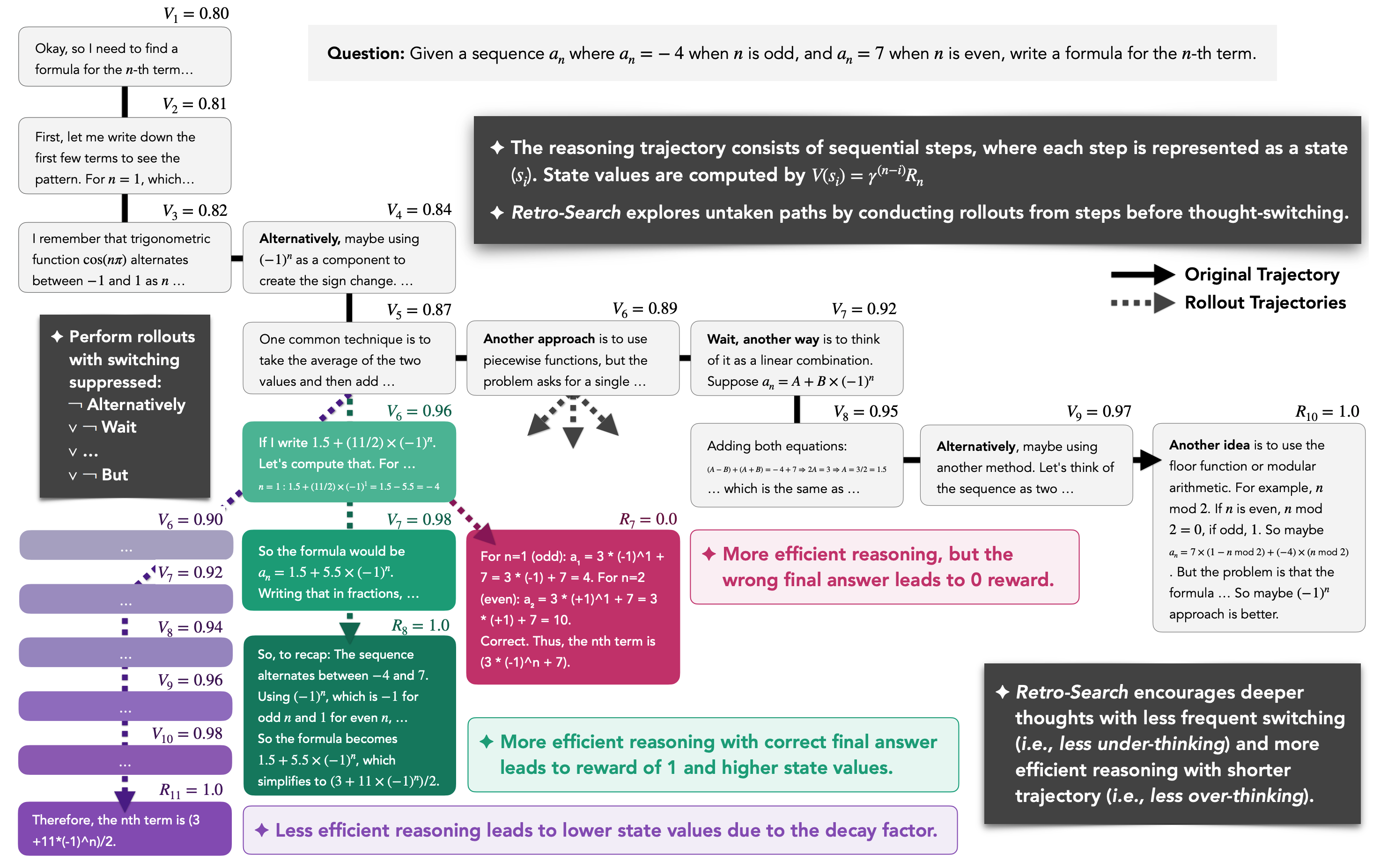
Ximing Lu*, Seungju Han*, David Acuna Marrero*, Hyunwoo Kim* Jaehun Jung*, Shrimai Prabhumoye, Niklas Muennighoff, Mostafa Patwary, Mohammad Shoeybi, Bryan Catanzaro, Yejin Choi preprint, 2025 paper / bibtex Search-guided distillation mitigates under-thinking & over-thinking of reasoning models, while simultaneously improving the accuracy. |
|
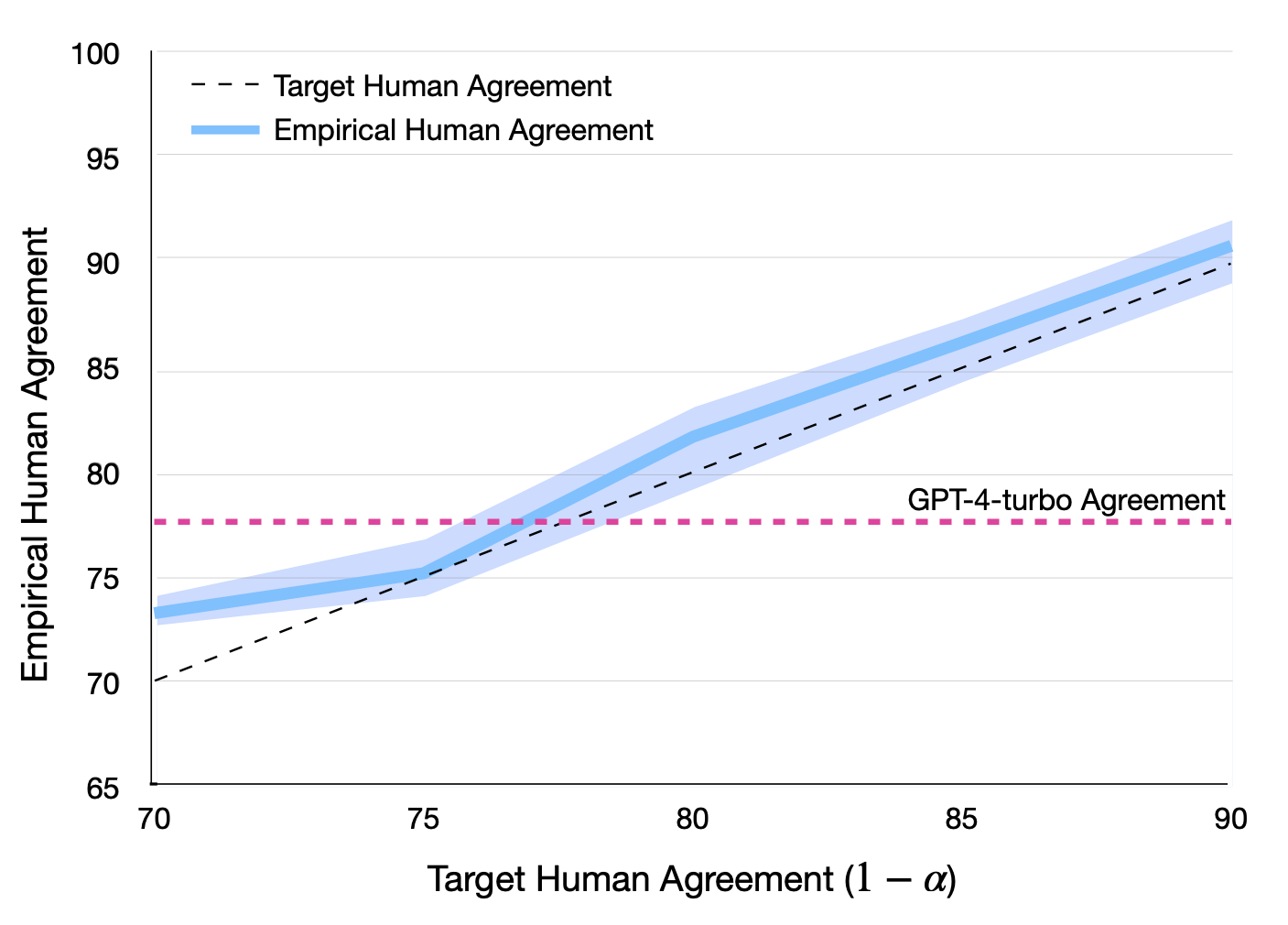
Jaehun Jung, Faeze Brahman, Yejin Choi ICLR, 2025 (Oral, Top 1.8%) paper / bibtex We enhance LLM judges with a statistically rigorous guarantee of human agreement. We further extend this guarantee to propose Cascaded Selective Evaluation, where we start from a small cost-effective model as a judge, and escalate to a stronger model only when necessary—all while guaranteeing high agreement with humans. |

|
Jaehun Jung, Ximing Lu, Liwei Jiang, Faeze Brahman, Peter West, Pang Wei Koh, Yejin Choi COLM, 2024 paper / bibtex Can small models excel at summarization without imitating LLM or human-written references? We present InfoSumm, a framework to distill a powerful summarizer that outperforms order-of-magnitude larger LLM summarizers, solely based on the information-theoretic objective for summarization. |

|
Jaehun Jung, Peter West, Liwei Jiang, Faeze Brahman, Ximing Lu, Jillian Fisher, Taylor Sorensen, Yejin Choi NAACL, 2024 paper / data / bibtex It is possible to generate a high-quality dataset for sentential paraphrasing and summarization directly from an off-the-shelf LM, even when it is impossible for the LM itself to reliably perform these tasks. |

|
Jillian Fisher, Ximing Lu, Jaehun Jung, Liwei Jiang, Zaid Harchaoui, Yejin Choi NAACL, 2024 (Oral Presentation) paper / github / bibtex We introduce JamDec, an inference-time algorithm for authorship obfuscation that is domain-agnostic, controllable, yet does not require human supervision. |

|
Ximing Lu, Faeze Brahman, Peter West, Jaehun Jung, ..., Xiang Ren, Sean Welleck, Yejin Choi EMNLP, 2023 paper / github / bibtex Can we adapt LLMs without fine-tuning? We propose using a lightweight adapter (e.g. GPT-2) during decoding time, efficiently tailoring even the strongest proprietary LLMs toward user-defined reward. |

|
Skyler Hallinan, Faeze Brahman, Ximing Lu, Jaehun Jung, Sean Welleck, Yejin Choi Findings of EMNLP, 2023 paper / github / bibtex We propose a text style transfer framework from arbitrary source style to many target styles via large-scale data generation with expert-guided decoding and offline RL. |

|
Jaehun Jung, Lianhui Qin, Sean Welleck, Faeze Brahman, Chandra Bhagavatula, Ronan Le Bras, Yejin Choi EMNLP, 2022 (Oral Presentation) paper / github / bibtex We improve LM reasoning by generating abductive and recursive explanations from language models, then formulating inference as a satisfiability problem over these generations. |

|
Jaehun Jung, Jinhong Jung, U Kang KDD, 2021 paper / github / bibtex A novel GNN for temporal KG is proposed that encodes an interpretable graph substructure for knowledge graph completion. |

|
Jaehun Jung, Bokyung Son, Sungwon Lyu EMNLP, 2020 paper / video / bibtex We present a novel decoder model based on attention flow that learns to explore KG and retrieve a relevant knowledge path to ground a dialogue agent. |

|
Guhyun Han, Jaehun Jung, Youngho Kim Jinwook Seo CHI, 2023 paper / bibtex DataHalo implements a customizable notification visualization system for mobile devices, providing prolonged ambient visualizations based on time-varying importance model to enable longitudinal interaction with the notifications. |
|
Website design by Jon Barron |